









Every time ChatGPT takes three seconds to respond instead of 30, there’s probably infrastructure like vLLM working behind the scenes.
You’ve been using it without knowing it. And now, the team behind it just became an $800 million company overnight.
Here are the details
Today, Inferact launched with a massive $150 million seed round to commercialize the open-source inference engine that’s already powering AI at Amazon, major cloud providers, and thousands of developers worldwide. Andreessen Horowitz and Lightspeed led the round, with participation from Sequoia, Databricks, and others.
What actually is vLLM? Think of it as the difference between a traffic jam and an AI highway system. When you ask ChatGPT a question, your request goes through an “inference” process — the model generates your answer, word by word. vLLM makes that process drastically faster and cheaper through two key innovations:
PagedAttention: Manages memory like your computer handles RAM, cutting waste by up to 24x compared to traditional methods.
Continuous batching: Instead of processing one request at a time, vLLM handles multiple requests simultaneously, like a restaurant serving 10 tables at once instead of waiting for each person to finish before seating the next.
Companies using vLLM report inference speeds 2-24x faster than standard implementations, with dramatically lower costs. The project has attracted over 2,000 code contributors since launching in 2023 from UC Berkeley’s Sky Computing Lab.
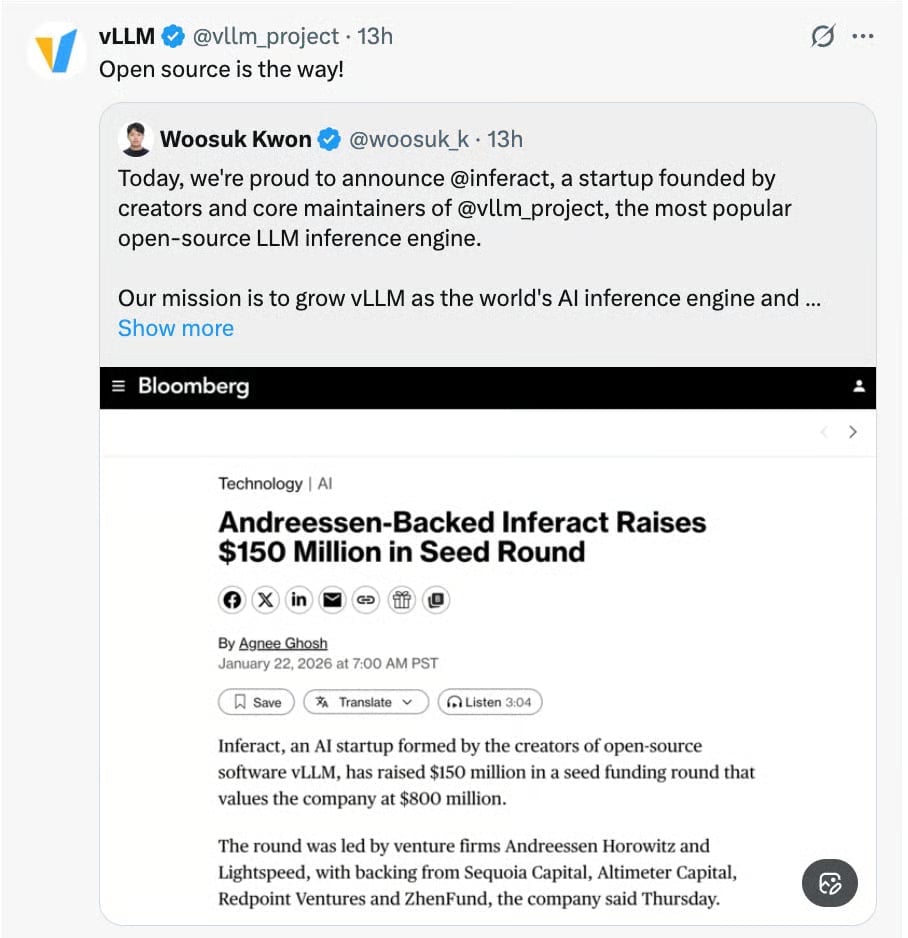
Image: X
Why this matters
AI is shifting from a training problem to a deployment problem.
Building a smart model is no longer the bottleneck (all the main models are good), running it affordably at scale is. As companies move from experimenting with ChatGPT to deploying AI across millions of users this year, inference optimization becomes the difference between profit and bankruptcy.
Expect every major AI company to obsess over inference economics in 2026. The winners won’t necessarily be the smartest models, but the ones that can serve predictions fast enough and cheaply enough to actually make money.
For you: If your company is evaluating AI tools, ask vendors about their inference infrastructure. Tools built on engines like vLLM will scale more cost-effectively than proprietary solutions that haven’t solved this problem. The open-source advantage here is real… and now, venture-backed.
Editor’s note: This content originally ran in the newsletter of our sister publication, The Neuron. To read more from The Neuron, sign up for its newsletter here.