







Machine learning is still in its infancy, and this is especially true at the tooling level, where workflows are simplistic, hacked together or prohibitively complicated to orchestrate. Also, there are few tools that equally satisfy the machine learning engineer, the infrastructure engineer and the engineering manager.
What are the consequences of stitching together various open-source tools to build machine learning workflows? How much productivity is lost, and who loses out?
The short answer is “everyone.” According to one source, an enterprise can take six to 18 months to deploy a single ML model to production. Another estimate concludes that data scientists are spending up to 90% of their time on infrastructure tooling rather than building models.
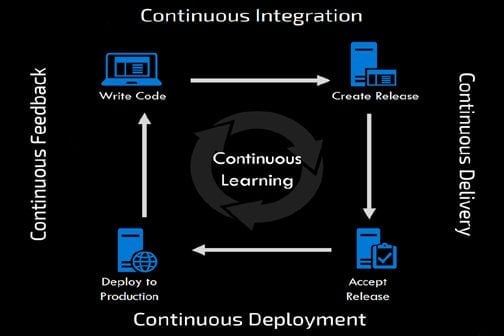
The consequences are dramatic. The good news is that much can be learned from the web software development cycle and, in particular, the concept of CI/CD (continuous integration and continuous delivery).
Implementing CI/CD techniques for ML brings rapid improvement in model delivery to the enterprise by substantially shortening the development cycle and enabling data scientists to produce business value faster.
In this eWEEK Data Points article, Dillon Erb, CEO at Paperspace, discusses the how CI/CD is reshaping the world ML development.
Data Point No. 1: Shortening the Development Cycle
The most important consideration for a data science team is how quickly it can bring to production a model that drives business value. Too often data science teams get mired down in the complexity of the development process and find themselves unable to collaborate, iterate and deploy successfully.
The key to improving model velocity is to use a toolstack that supports CI/CD. Since the desired goal is to move swiftly from research to production, a good ML platform will make it easy to operationalize, test and deploy a model.
These are the features that should be prioritized:
- Push code from a source control management (SCM) system directly to production
- Pull, branch or fork ML code in a way that is visible to the entire team
- Loop outputs back into the input process
- Work from the command line or from a GUI
- Visualize results and outputs to inform future development
Data Point No. 2: Improving Team Visibility and Collaboration
With hacked-together tools, complexity rises exponentially as a data science team grows. Any CI/CD workflow in an ML environment must have a feature set that enables seamless collaboration.
Borrowing from traditional software collaboration techniques, CI/CD for ML uses source control and a repeatable orchestration system. By proceeding this way, versions are properly managed, team members each have visibility, and code may be pushed to production with a single command or as part of an automated workflow.
Data Point No. 3: Improving Failure Identification
Fault identification can be difficult in ML given the number of interweaving technologies required to deploy a model into production. With a CI/CD workflow, each step in the deployment process is automated, which means that the system as a whole is deterministic and resilient.
A leading CI/CD platform will provide real-time bug reporting in the UI as well as in the source control management system.
Data Point No. 4: Improving Reproducibility
Reproducibility is a common headache for ML workflows. As another unwelcome side effect of hacking together various tools to build a workflow, a lack of reproducibility can set back a model deployment by many weeks.
CI/CD platforms add a level of determinism to the process from research to production. When infrastructure is fully managed and code is correctly versioned, an ML pipeline can gain exceptional efficiencies.
Data Point No. 5: Cost Dependability
Compute costs can scale out of control without a CI/CD solution. A good CI/CD platform will take advantage of a job runner to allocate the exact amount of compute required for each training job with no wasted excess. This type of “serverless” execution environment enables precise control of compute costs and provides visibility into the true cost of training models.
Equally important, a job runner enables seamless upgrading to complex distributed training on many machines or in multiple clouds while maintaining precise oversight of costs. Distributed training otherwise presents immense technical and financial difficulties for data science teams.
Data Point No. 6: In Summary …
Effortless ML means writing ML code, not troubleshooting infrastructure tooling. A unified CI/CD platform provides an enterprise team with access to the entire stack—from the compute layer up through the management layer—while abstracting away tooling tasks that don’t scale.
Ultimately, a successful implementation of CI/CD in an ML development environment will mean greater collaboration, reliability, reproducibility, lower costs and, most importantly, a way shorter development cycle.
If you have a suggestion for an eWEEK Data Points article, email cpreimesberger@eweek.com.