






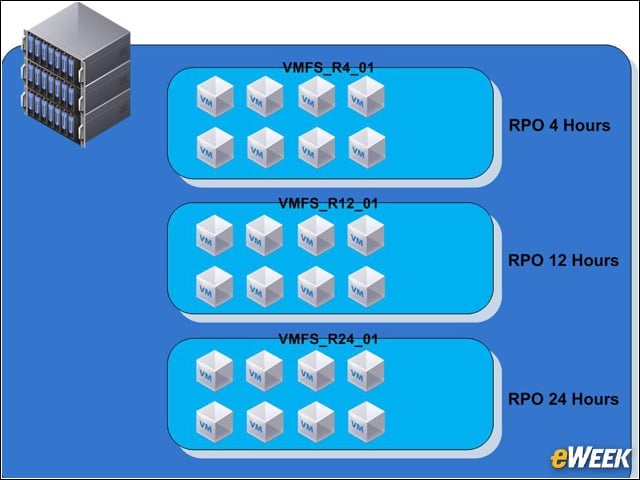

Data Snapshots to Protect Data
Without snapshots (of all the data in a storage device), if a user accidentally deletes a file, the deletion is replicated three times and the data is lost. The same applies to application data corruption. Many Hadoop users have lost valuable data due to such incidents. With snapshots, users can easily recover data to a point in time, the same way they would in any enterprise-class file system.
Data Mirroring for Backup
Mirroring data between clusters is useful for disaster recovery or remote backup, as well as for scenarios where the enterprise needs to have a production cluster and a research cluster.
Rolling Software Upgrades

Like other enterprise environments, Hadoop distributions should support a zero-downtime method for upgrading software with continuous availability to users.
Multi-tenancy for Application-Sharing
Multi-tenancy capabilities ensure the ability to effectively share a cluster across users and provide solutions to handle quotas, isolation and volumes.
Performance and Scale
Enterprise Hadoop should scale to support an unlimited number of files by simply adding nodes to increase the number of files supported.
High Availability
High availability with automated stateful failover and self-healing is essential in every enterprise environment. As businesses roll out Hadoop, the same set of standards should apply as for other enterprise applications. With automated stateful failover and high availability, enterprises can eliminate single points of failure from unplanned and planned downtime to protect users against the unexpected.
Ability to Integrate Into Existing Environments

The limitations of the Hadoop Distributed File System require whole-scale changes to existing applications and extensive development of new ones. Enterprise-grade Hadoop requires full random/read support and direct access with NFS (Network File System) to simplify development and ensure business users can access the information they need directly.
Ease of Use

With mainstream adoption comes the need for tools that don’t require specialized skills and programmer services. New Hadoop developments must be simple for users to operate and to explore patterns in the data. This includes direct access with standard protocols from existing tools and applications without changing applications or the deployment of special connectors or clients.
Simplified Data Management

With clusters constantly expanding well into the petabyte range, simplifying how data is managed is critical. The next generation of Hadoop distributions should include volume management to make it easy to apply policies across directories and file contents without managing individual files. These policies include data protection, retention, snapshots and access privileges.
Ease of Development
Simply put, the limitations of the Hadoop Distributed File System require wide-scale changes to existing applications and extensive development of new ones. The next-generation storage services layer provides full random/read support and provides direct access with NFS. This dramatically simplifies development. Existing applications and workflows can be used and just the specific steps requiring parallel processing need to be converted to take advantage of the MapReduce framework.