








Cloud data lakes are an increasingly critical complement to enterprises’ data warehouses. Their promise now goes well beyond more traditional notions of centralized storage to also incorporate what’s needed for data ingestion, analytics, data engineering, and artificial intelligence and machine learning initiatives. Get it right, and you unlock higher-value data insights that can steer myriad business initiatives for the long haul. See it go off the rails and … well, at least you’re not alone.
Gartner attracted headlines for tabbing the failure rate of data lake and big data projects at 60% back in 2016, only to revise that upto 85% the following year. Yet demand for data lakes has only increased, since enterprises understand the need.
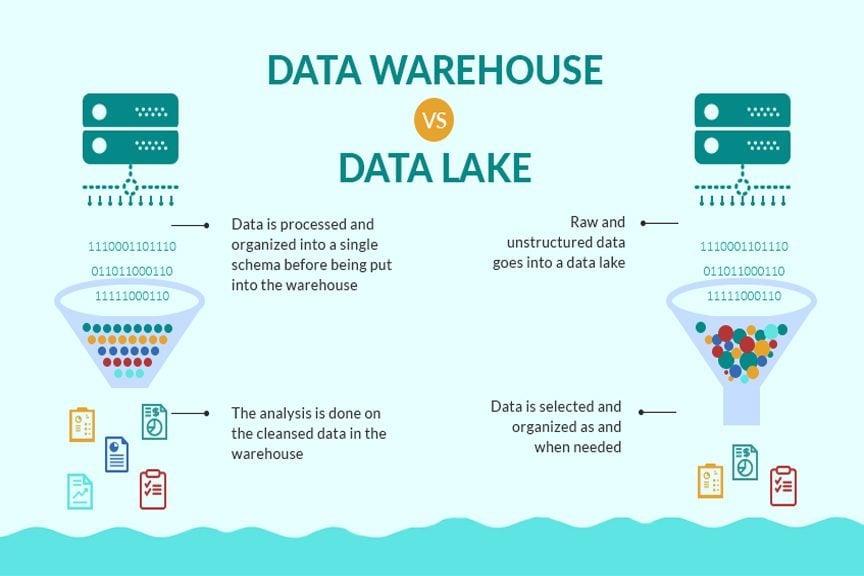
[To see a larger view of the image at top left, right-click on it and select “View Image.”]
Gartner research from earlier this year found that 52% of enterprises plan to invest in a data lake within the next two years. Whether the failure rate stays high depends on overcoming acute challenges. Talent is expensive and isn’t all that scalable for most organizations anyway.
- Investments in cloud data lakes can run well into seven figures
- Data Point No. 1: Achieving end-to-end orchestration of cloud data lakes isn’t easy.
- Data Point No. 2: Runaway costs and performance degradation occur without relentless monitoring and management.
- Data Point No. 3: Ensuring security, regulatory compliance and governance can be tricky.
- Data Point No. 4: Hybrid architecture and multi-cloud support is required.
- Data Point No. 5: Those who need the data need to be able to get to it themselves.
- Data Point No. 6: The Takeaway
Investments in cloud data lakes can run well into seven figures
Achieving a production cloud data lake deployment can typically take six to nine months of development. Annual investments required to maintain implementations can reach well into the seven figures, requiring teams of DevOps, security pros, and cloud experts. These requirements and the complexity they represent quickly prove overwhelming for enterprises seeking the benefits of cloud data lakes without the correct plan of attack in hand.
The most common cloud data lake setup–the do-it-yourself variety embraced by early adopters and digital natives–usually entails utilizing a native cloud PaaS stack that’s been assembled from a vast and labyrinthine array of technologies. Teams must navigate the many hundreds of PaaS choices and architectures available, while addressing the developmental, operational and security requisites of integrating each solution within their DIY cloud data lake implementation. Too often this task proves to be more than organizations without fully capable (and yes, costly) DevOps teams can realistically manage.
In this edition of eWEEK Data Points, Lovan Chetty, Vice-President at instant cloud data lake provider Cazena, shares his industry information about five specific struggles that enterprises must plan for in their cloud data lake journey
Data Point No. 1: Achieving end-to-end orchestration of cloud data lakes isn’t easy.
In order to manifest a cloud data lake as a singular, integrated and complete production instance, a disparate stack of technologies must be orchestrated and validated. This includes cloud storage, data ingestion, compute engines, security controls, identity management, networking access and analytics tools. The fact that several components of the data lake stack may be on-premises–such as analytics tools, analytics users and data sources–is usually a big contributor to the challenge of achieving this functional, hybrid and efficient end-to-end orchestration.
Data Point No. 2: Runaway costs and performance degradation occur without relentless monitoring and management.
The success of any cloud data lake project hinges on continual changes to maximize performance, reliability and cost efficiency. Each of these variables require constant and detailed monitoring and management of end-to-end workloads. Consider the evolution of data processing engines and the importance of leveraging the most advantageous opportunities around price and performance. Managing workload price performance and cloud cost optimization is just as crucial to cloud data lake implementations, where costs can and will quickly get out of hand if proper monitoring and management aren’t in place.
Data Point No. 3: Ensuring security, regulatory compliance and governance can be tricky.
Public cloud resources aren’t private by default. Securing a production cloud data lake requires extensive configuration and customization efforts–especially for enterprises that must fall in line with specific regulatory compliance oversights and governance mandates (HIPAA, PCI DSS, GDPR, etc). Achieving the requisite data safeguards often means enlisting experienced and dedicated teams who are equipped to lock down cloud resources and restrict access to only users that are authorized and credentialed.
Once robust authorization and access controls are in place that protect a cloud data lake, teams must continue to monitor and control a fluid analytic environment containing sensitive and confidential data while also enforcing regulatory compliance and effective data governance policies.
Data Point No. 4: Hybrid architecture and multi-cloud support is required.
There’s dangerous potential for disconnect between on-prem data sources and analytics users on one side, and the cloud data lake resources in the public cloud on the other. Cloud data lakes are typically part of a hybrid architecture that enables them to function as an extension of enterprise data environments. Cloud data lakes need to support data pipelines that can span both on-premises sources, as well as cloud sources or third-party data sources and processes. Ensuring that global analytics users can leverage cloud data lakes seamlessly takes close monitoring, management and security backed by robust end-to-end SLAs.
Enabling multi-cloud architecture also expands the utility and possibilities of cloud data lakes, ensuring their portability across cloud providers without disruptions to data flows or analytics workflows. Enterprises who will need multi-cloud options should build this capability into their platform from the beginning; it’s far more challenging to add later.
Data Point No. 5: Those who need the data need to be able to get to it themselves.
Enterprises do well to focus on the users their data lakes are for: the data scientists, data engineers, analysts and product teams that coax out insights and press them into action. A strong definition of a successful cloud data lake is one that enables those who need the data to rapidly access, consume and put data to work–no matter their tools or location.
While challenging to implement, self-service functionality is essential for allowing users without development or operations skillsets to still leverage the cloud data lake using existing AI/ML, BI, search, and data tools (or even new ones hosted with the data lake itself).
Data Point No. 6: The Takeaway
While each of the capabilities discussed is a must-have for a modern cloud data lake, they also show the cost and implementation challenges enterprises must navigate to get there. It is estimated that enterprises invest 5-6 DevOps dollars on expertise for each dollar of investment in the cloud stack. In shaping their cloud data lake approach, enterprises should seek out a strategy that can simplify these challenges and reduce the need for expertise.
By lowering these hurdles–or avoiding them altogether–enterprises can have their data science and analytics teams reap the benefits of cloud data lake implementations while operating as efficiently as possible and within their budgets.
If you have a suggestion for an eWEEK Data Points article, email cpreimesberger@eweek.com.