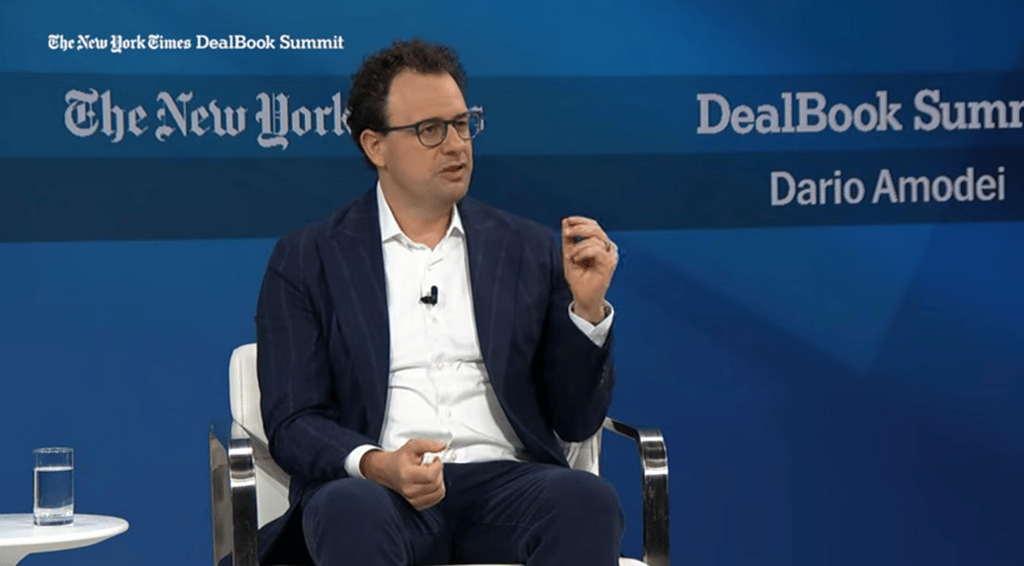
Dr. Chris Hillman, Global AI Lead at Teradata, joins eSpeaks to explore why open data ecosystems are becoming essential for enterprise AI success. In this episode, he breaks down how openness — in architecture, tools, and partnerships like Teradata + AWS — helps organizations accelerate innovation, scale securely, and future-proof their AI strategies.

eSpeaks host Corey Noles sits down with Qualcomm's Craig Tellalian to explore a workplace computing transformation: the rise of AI-ready PCs.

Matt Hillary, VP of Security and CISO at Drata, details problems and solutions as AI plays an expanding role in governance, risk, and compliance (GRC).

-
Latest News - Resources Featured ResourcesLink to The Real AI Power Play: Who Controls Your Enterprise Data Layer? The Real AI Power Play: Who Controls Your Enterprise Data Layer?IT and data teams were promised that AI would make work easier. Instead, it's created new layers of complexity.Link to Building the Backbone of Agentic AI with Trusted, Context-Rich Data Building the Backbone of Agentic AI with Trusted, Context-Rich DataIn this 10-minute take video, Reltio Principal Solutions Consultant Guy Vorster explains how organizations can overcome fragmented data challenges to power AI agents.Link to IHG scales real-time, trusted data across global brands IHG scales real-time, trusted data across global brandsAccelerating time to value while powering data-driven engagementLink to eSpeaks: BYOM with Teradata’s Dr. Chris HillmaneSpeaks: BYOM with Teradata’s Dr. Chris Hillman
Dr. Chris Hillman, Global AI Lead at Teradata, joins eSpeaks to explore why open data ecosystems are becoming essential for enterprise AI success. In this episode, he breaks down how openness — in architecture, tools, and partnerships like Teradata + AWS — helps organizations accelerate innovation, scale securely, and future-proof their AI strategies.
Link to Qualcomm’s Craig Tellalian on AI-Ready Enterprise PCsQualcomm’s Craig Tellalian on AI-Ready Enterprise PCseSpeaks host Corey Noles sits down with Qualcomm's Craig Tellalian to explore a workplace computing transformation: the rise of AI-ready PCs.
Link to Drata’s Matt Hillary on AI’s Role in Compliance and GovernanceDrata’s Matt Hillary on AI’s Role in Compliance and GovernanceMatt Hillary, VP of Security and CISO at Drata, details problems and solutions as AI plays an expanding role in governance, risk, and compliance (GRC).
-
Artificial Intelligence -
Video -
Big Data & Analytics -
Cloud -
Networking - Cybersecurity Cybersecurity
- Applications Applications
- IT Management IT Management
- Storage Storage
- Mobile Mobile
- Small Business Small Business
- Development Development
- Database Database
- Servers Servers
- Android Android
- Apple Apple
- Innovation Innovation
- PC Hardware PC Hardware
- Reviews Reviews
- Search Engines Search Engines
- Virtualization Virtualization
-
- Blogs Blogs