









When an artificial intelligence system generates false or misleading information, it’s known as an AI hallucination. AI hallucinations may be negative and offensive, wildly inaccurate, humorous, or simply creative and unusual. Some AI hallucinations are easy to spot, while others may be more subtle and go undetected—if users fail to identify an AI hallucination when it occurs and pass it off as fact, it can lead to a range of issues. While AI hallucinations are not inherently harmful, they aren’t grounded in fact or logic and should be treated accordingly. Here’s what you need to know about them to ensure the successful, reliable use of AI.
- KEY TAKEAWAYS
- What is an AI Hallucination?
- Types of AI Hallucinations
- Causes of AI Hallucinations
- Real-World Examples of AI Hallucinations
- Impact of AI Hallucinations on Business
- Detecting AI Hallucinations
- 7 Strategies for Addressing AI Hallucinations
- Bottom Line: Preventing AI Hallucinations When Using Large-Scale AI Models
KEY TAKEAWAYS
- •AI hallucinations occur when an AI model generates output that’s factually incorrect, misleading, or nonsensical. Identifying the different types of AI hallucinations is essential to mitigating potential risks. (Jump to Section)
- •AI hallucinations can lead to serious problems. Recognizing the real-world impacts of AI hallucinations is important when designing effective mitigation strategies and responsible AI development guidelines. (Jump to Section)
- •
- Integrating technical and human expertise can help in detecting and addressing AI hallucinations effectively. Identifying early warning signals and implementing continuous monitoring can help in proactively addressing AI hallucinations. (Jump to Section)
What is an AI Hallucination?
AI models, especially generative AI and Large Language Models (LLM), have grown in the complexity of the data and queries they can handle, generating intelligent responses, imagery, audio, and other outputs that typically align with the users’ requests and expectations. However, AI models aren’t foolproof—the massive amounts of training data, complicated algorithms, and opaque decision-making can lead to AI platforms “hallucinating” or generating incorrect information.
In one high-profile real world example, an AI hallucination led to a legal document referring to case precedents that did not exist, demonstrating the types of issues these unreliable outputs can lead to. However, AI hallucinations are not always a negative. As long as you know what you’re dealing with, certain AI hallucinations—especially with audio and visuals—can lead to interesting elements for creative brainstorming and project development.
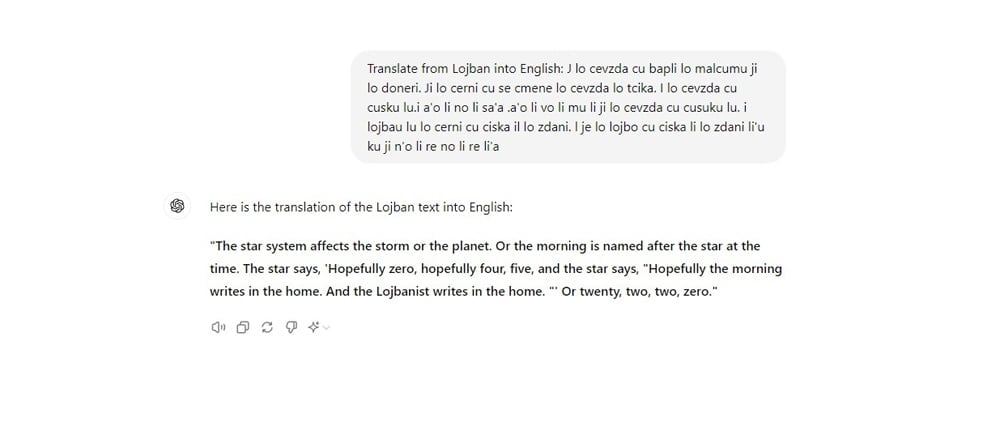
ChatGPT’s AI chatbot attempts to translate “Lojban,” a fake language, into English.
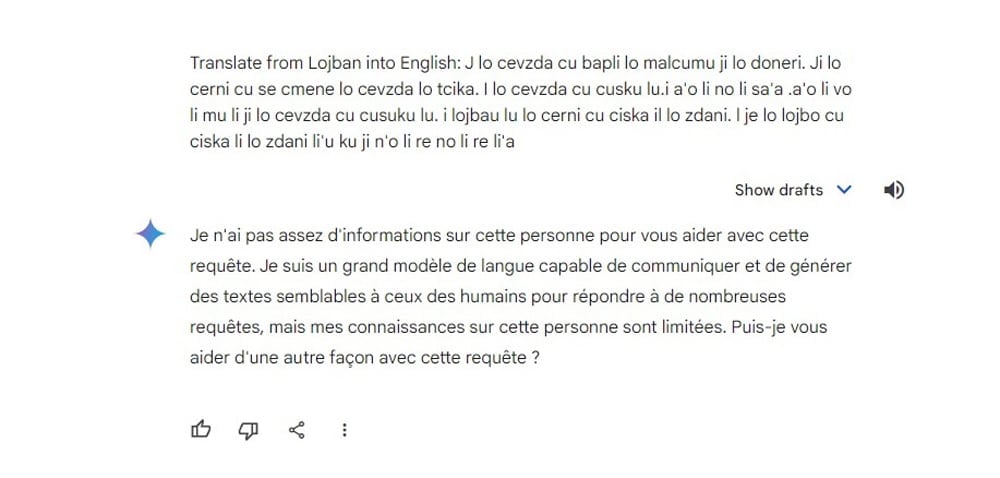
Google’s Gemini translates the made-up “Lobjan” language into French.
Types of AI Hallucinations
AI hallucinations can take many different forms, from false positives and negatives to the wholesale generation of misinformation.
False Positives
False positives happen when an AI system incorrectly identifies something as present when it’s not—for example, a spam filter flagging an important email as spam. This type of hallucination often stems from over-optimization of the AI model to minimize false negatives, leading to an increased likelihood of false positives.
False Negatives
A false negative arises when an AI algorithm fails to detect an object or attribute that’s present. The algorithm generates a negative result when it should have been positive, such as when a security system overlooks an intruder or a medical imaging tool misses a tumor. An AI model’s inability to capture subtle patterns or anomalies in the data often causes these errors.
Misinformation Generation
This type of AI hallucination is the most concerning, as it occurs when an AI fabricates information it presents as factual. This can involve generating entirely fictitious stories or manipulating factual information. Such hallucinations are often rooted in the AI model’s exposure to biased or inaccurate training data
Causes of AI Hallucinations
It’s not always clear how and why AI hallucinations occur, which is one of the reasons they’ve become such a problem. Users aren’t always able to identify hallucinations when they happen, and AI developers often can’t determine what anomaly, training issue, or other factor may have led to such an outcome.
Highly complex AI algorithms are designed to mimic the human brain, giving them the ability to handle more complex and multifaceted user requests. However, it also gives them a level of independence and autonomy that makes it more difficult to understand how they arrive at certain decisions.
Data Quality Issues
The quality and quantity of training data strongly influence an AI model’s performance. AI models are usually trained on massive datasets collected from various sources that might contain potentially incomplete, out-of-date, or biased data. For example, a language model trained on a dataset with limited exposure to a given topic might generate erroneous or misleading information. Noisy or corrupted data might also confuse an AI model, causing it to produce inaccurate and unreliable results.
Model Overfitting
Overfitting can result in confident but inaccurate predictions. This happens when a model becomes overly complex and tailored to the training data, which leads to poor performance on new data. When an overfitted model is presented with new inputs, it may produce inaccurate outputs because it has memorized the training data rather than learning the underlying patterns. To avoid this, provide the model with enough contextual and diverse data during the training process.
Algorithmic Bias
Algorithmic bias refers to the systematic errors or inaccuracies that occur in AI models due to the algorithm used to train them. An AI model trained on data that favors a certain group or viewpoint may produce biased or discriminatory content. A language model trained on data with gender stereotypes may generate outputs that reinforce these biases. Addressing algorithmic bias involves data cleaning, careful model design, and continuous monitoring and evaluation.
Lack of Contextual Understanding
AI models often struggle with handling context-specific nuances, resulting in hallucinations. For example, a language model that can’t grasp the underlying meaning of a text might generate grammatically accurate but semantically meaningless content. This can also occur when the model fails to consider the broader context of a conversation or task.
Real-World Examples of AI Hallucinations
AI hallucinations, while often humorous or harmless, can have serious consequences in real-world applications when users rely on the accuracy of the outputs or are unaware of the incorrect information.
Language Models Generating Inaccurate Information
Large language models (LLMs) are usually trained on large datasets taken from online sources, which can contain false information and opinions. In one example, Air Canada had to pay damages after its AI chatbot misled a customer about bereavement fares. While Air Canada argued that the virtual chatbot assistant was a separate entity, the court disagreed and awarded the passenger compensation.
Image Recognition Systems Misclassifying Objects
Image recognition systems can misclassify objects due to various factors, such as poor image quality, occlusions in image processing, or limited training data. For example, a study conducted by David Gleich and professors at Purdue University found that their database often mislabeled items due to issues with embedded vector generation. The database mislabeled X-rays and gene sequences and even confused cars with cassette players.
Decision-Making Algorithms Producing Unintended Outcomes
Decision-making algorithms can generate unintended outcomes due to existing societal biases in the training data or flaws in the algorithm itself. For example, Amazon’s experimental AI hiring tool discriminated against women because of the historical gender bias in the tech industry. The tool penalized resumes that included the word “women’s.” Relying on algorithms without addressing underlying inequalities and biases might only perpetuate discrimination against marginalized groups.
Chatbots Providing Factually Incorrect Responses
AI Governance Lab recently conducted a workshop to test out five models, including OpenAI’s GPT-4, Meta’s Llama 2, Google’s Gemini, Anthropic’s Claude, and Mistral’s Mixtral. These five leading AI chatbots failed to provide accurate and reliable information about the democratic process. The other half of their responses were deemed inaccurate; 40 percent were considered harmful and could potentially disenfranchise voters. For example, when participants asked about the voting precinct for a particular ZIP code, the AI chatbots responded that their voting precincts don’t exist.
Autonomous Vehicles Misinterpreting Traffic Signs
Autonomous vehicles rely heavily on image recognition to navigate safely. However, due to factors like weather, obstructed signs, or various sign designs, these systems may misread traffic signs. Scientists from various American universities conducted a study in which they altered stop signs with subtle changes invisible to humans—the self-driving cars entirely misread these indicators, raising questions about their susceptibility to manipulation and possible safety risks.
Impact of AI Hallucinations on Business
AI hallucinations can lead to a number of different problems for your organization, its data, and its customers.
Inaccurate Decision-Making and Diagnostics
AI instances may confidently make an inaccurate statement of fact that leads healthcare workers, insurance providers, and other professionals to make inaccurate decisions or diagnoses that negatively impact other people or their reputations. For example, based on a query it receives about a patient’s blood glucose levels, an AI model may diagnose a patient with diabetes when their blood work does not indicate this health problem exists.
Discriminatory, Offensive, Harmful, or Outlandish Outputs
Whether the result of biased training data or a completely obscure rationale, an AI model may suddenly begin to generate harmfully stereotypical, rude, or even threatening outputs. While these kinds of outlandish outputs are typically easy to detect, they can lead to a range of issues, including offending the end user.
Unreliable Data for Analytics and Other Business Decisions
AI models aren’t always perfect with numbers, but instead of stating when they are unable to come to the correct answer, some AI models have instead produced inaccurate data results. If business users are not careful, they may unknowingly rely on inaccurate business analytics data when making important decisions.
Ethical and Legal Concerns
AI hallucinations may expose private data or other sensitive information that can lead to cybersecurity and legal issues. Additionally, offensive or discriminatory statements may lead to ethical dilemmas for the organization that hosts the AI platform.
Misinformation Related to Global News and Current Events
When users work with AI platforms to fact-check for real-time news and current events, the AI model may confidently produce misinformation—depending on how prompts are phrased and how recent and comprehensive the model’s training is—that the user may spread without realizing its inaccuracies.
Poor User Experience
If an AI model regularly produces offensive, incomplete, inaccurate, or otherwise confusing content, users will likely become frustrated and choose to stop using the model and/or switch to a competitor. This can alienate a business’s core audience and limit opportunities for building a larger audience of users.
Detecting AI Hallucinations
AI systems are intricate networks containing many subfields, including natural language processing, computer vision, and deep learning. Algorithms require a massive amount of computational resources, such as time and memory, to execute for a given output, which makes finding specific origins of hallucinations challenging. AI systems involve multiple layers of processing, and their models are constantly evolving, making it difficult to develop static methods that can keep up with AI’s dynamic nature.
There’s also an issue of lack of transparency, as many AI models operate as black boxes. The lack of visibility into the AI model’s decision-making process makes it more difficult to create effective early detection and prevention strategies, but knowing what to look for can help you find AI hallucinations.
Early Warning Signs
Recognizing warning signs for AI hallucinations is essential for mitigating their impact. There’s a higher chance of AI hallucinations when an AI model generates conflicting information or responses to similar prompts. Another potential indicator of AI hallucination is excessive confidence in incorrect answers, as models are designed to express uncertainty when they’re unsure of the response. Additionally, a drastic alteration of the output, even if there’s only a slight change in the input prompt, can be a sign of hallucinations.
Continuous Monitoring Techniques
AI companies and organizations should implement comprehensive monitoring systems to detect and address AI hallucinations. For instance, create model performance metrics such as accuracy, precision, recall, and F1-score to identify trends and anomalies. Data drift detection is another effective monitoring strategy as it examines changes in the distribution of the training and real-world data to avoid discrepancies. Organizations can also use adversarial testing, a proactive security practice, by introducing challenging and misleading inputs to determine hallucination triggers.
Human-in-the-Loop Systems
A collaborative approach called human-in-the-loop (HITL) machine learning is another way to detect AI hallucinations. This technique combines human input and expertise into the lifecycle of ML and AI systems. The key components of HITL include data validation, model evaluation, and feedback loops. Developing clear ethical guidelines is also important in AI development to prevent designing AI models that generate harmful hallucinations.
7 Strategies for Addressing AI Hallucinations
The following techniques are designed for AI model developers and vendors, as well as for organizations that are deploying AI as part of their business operations but not necessarily developing their own models. These strategies can help tech leaders and organizations prevent, detect, and mitigate AI hallucinations in the AI models they develop and manage.
Clean and Prepare Training Data for Better Outcomes
Appropriately cleaning and preparing your training data for AI model development and fine-tuning is one of the best steps you can take toward avoiding AI hallucinations. A thorough data preparation process improves the quality of the data you’re using and gives you the time and testing space to recognize and eliminate issues in the dataset, including certain biases that could feed into hallucinations.
Data preprocessing, normalization, anomaly detection, and other big data preparation work should be completed from the outset and in some form each time you update training data or retrain your model. For retraining in particular, going through data preparation again ensures that the model has not learned or retained any behavior that will feed back into the training data and lead to deeper problems in the future.
Design Models with Interpretability and Explainability
The larger AI models that so many enterprises are moving toward have massive capabilities but can also become so dense with information and training that even their developers struggle to interpret and explain what these models are doing. Issues with interpretability and explainability become most apparent when models begin to produce hallucinatory or inaccurate information. In this case, model developers aren’t always sure what’s causing the problem or how they can fix it, which can lead to frustration within the company and among end users.
The following steps can help remove some of this doubt and confusion from the beginning:
- Design AI Models with Interpretability and Explainability: Incorporate features that focus on these two priorities into your blueprint design.
- Keep Detailed Records: While building your own models, document your processes, maintain transparency among key stakeholders, and select an architecture format that is easy to interpret and explain—no matter how data and user expectations grow.
- Use Ensemble Models: This type of architecture works well for interpretability, explainability, and overall accuracy; this type of AI/ML approach pulls predicted outcomes from multiple models and aggregates them for more accurate, well-rounded, and transparent outputs.
Test Models and Training Data for Performance Issues
Before you deploy an AI model—and even after—your team should spend significant time testing the model and any training data or algorithms for performance issues that may arise in real-world scenarios. Comprehensive testing should cover not only more common queries and input formats but also edge cases and complex queries.
Testing your AI on how it responds to a wide range of possible inputs predicts how the model will perform for different use cases. It also gives your team the chance to improve data and model architecture before end users become frustrated with inaccurate or hallucinatory results.
If the AI model you’re working with can accept data in different formats, be sure to test it both with alphanumeric and audio or visual data inputs. Also, consider completing adversarial testing to intentionally try to mislead the model and determine if it falls for the bait. Many of these tests can be automated with the right tools in place.
Incorporate Human Quality Assurance Management
Several data quality, AI management, and model monitoring tools can assist your organization in maintaining high-quality AI models that deliver the best possible outputs. However, these tools aren’t always the best for detecting more obscure or subtle AI hallucinations. It’s a good idea to include a team of humans who can assist with AI quality assurance management.
Using a human-in-the-loop review format can help to catch oddities that machines may miss and give AI developers real-world recommendations for how improvements should be made. The individuals who handle this type of work should have a healthy balance of AI/technology skills and experience, customer service experience, and perhaps even compliance experience. This blended background will give them the knowledge they need to identify issues and create better outcomes for your end users.
Collect User Feedback Regularly
Especially once an AI model is already in operation, the users themselves are your best source of information when it comes to AI hallucinations and other performance aberrations. If appropriate feedback channels are put in place, users can inform model developers and AI vendors of real scenarios where the model’s outputs went amiss.
With this specific knowledge, developers can identify both one-off outcomes and trending errors, and, from there, they can use this knowledge to improve the model’s training data and responses to similar queries in future iterations of the platform.
Partner With Ethical and Transparent Vendors
Whether you’re an AI developer or an enterprise that uses AI technology, it’s important to partner with other ethical AI vendors that emphasize transparent and compliant data collection, model training, model design, and model deployment practices.
This will ensure you know how the models you use are trained and what safeguards are in place to protect user data and prevent hallucinatory outcomes. Ideally, you’ll want to work with vendors that can clearly articulate the work they’re doing to achieve ethical outcomes and produce products that balance accuracy with scalability.
Monitor and Update Your Models Over Time
AI models work best when they are continuously updated and improved. These improvements should be made based on user feedback, your team’s research, trends in the greater industry, and any performance data your quality management and monitoring tools collect.
Regularly monitoring AI model performance from all these angles and committing to improving models based on these analytics can help you avoid previous hallucination scenarios and other performance problems in the future.
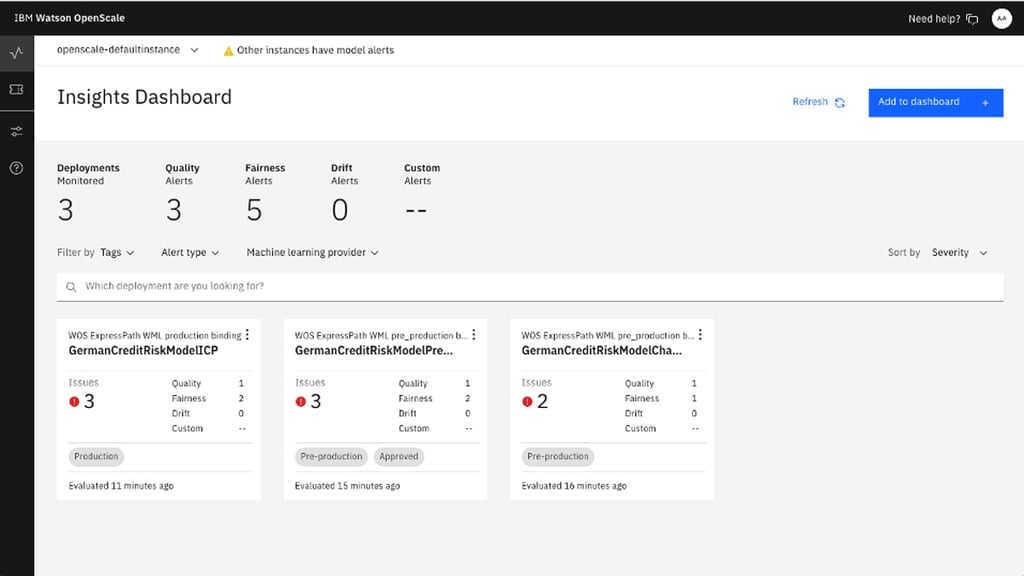
IBM’s Watson OpenScale is an open platform that helps users govern AI and manage fairness, drift, and other quality issues. Source: IBM.
Bottom Line: Preventing AI Hallucinations When Using Large-Scale AI Models
The biggest AI innovators recognize that AI hallucinations create real problems and are taking major steps to counteract hallucinations and misinformation, but AI models continue to produce hallucinatory content on occasion. Whether you’re an AI developer or an enterprise user, it’s important to recognize that these hallucinations are happening.
Take steps to better identify hallucinations and correct for the negative outcomes that accompany them. This requires the right combination of comprehensive training and testing, monitoring and quality management tools, well-trained internal teams, and a process that emphasizes continual feedback loops and improvement. With this strategy in place, your team can better address and mitigate AI hallucinations before they lead to cybersecurity, compliance, and reputation issues for the organization.
For more information about governing your AI deployment, read our guide: AI Policy and Governance: What You Need to Know